
워드클라우드
1.1 워드 클라우드란?

위의 그림 처럼 단어들로 구성된 하나의 그림을 워드 클라우드 혹은 텍스트 클라우드 라고 합니다.
워드 클라우드는 문서의 핵심 키워드를 시각화 한 그림으로서 특정 문서 내의 어느 키워드가 많이 나타나고 있는지 한 눈에 볼 수 있다는 장점을 가지고 있습니다. 이러한 장점 덕분에 뉴스나 저널에서 시각화 자료로 많이 사용되곤 합니다.
이번 3차 세미나(2)의 목표는 세미나(1)에서 크롤링했던 음악 차트의 TOP 100 노래들의 가사를 워드 클라우드로 만들어서 우리나라의 음악들은 어떤 키워드로 하고 있는지 파악하는 것입니다. 제 생각으로는 우리나라는 특히 사랑과 관련된 노래가 많다고 평소 느끼는데요! 진짜 그럴지 확인해 보도록 합시다!
그럼 시작해 볼까요?
1.2 텍스트 데이터를 분석하기 위한 방법
자 우선! 워드 클라우드는 어떤 기술을 기반으로 하고 있는지 알고 넘어갈 필요가 있습니다!
많은 데이터 분석에서는 기사 내용, SNS 포스팅, 웹문서 등 처럼 사람의 언어 로 구성된 데이터를 분석하는 경우가 많습니다. 평소의 우리생활에 밀접하게 연관되어 있는 것이 언어 이기 때문에 사람들의 언어를 분석하면 좋은 데이터를 얻을 수 있기 때문이죠!
하지만 0과 1로 이루어진 컴퓨터는 사람들의 언어를 알아 들을 수 없습니다. 그렇다면 우리가 사용하는 언어를 컴퓨터가 이해할 수 있도록 바꿔주는 작업이 필요하겠죠??
사람들의 언어의 의미를 분석하여 컴퓨터가 처리할 수 있도록 하는 기술을 자연어 처리라고 합니다.
아래는 자세한 설명입니다!
자연어 처리(Natural language processing)란?
자연언어 혹은 자연어(Natural Language)는 사람들이 일상적으로 쓰는 언어를 뜻합니다. 우리는 같은 의미를 가지고 있는 단어들도 다양한 표현방식을 사용하죠. ‘사용하다’, ‘사용한다’, ‘사용합니다’, ‘사용했죠’ 등이 결국은 ‘사용하다’는 동사와 같은 것 처럼요. 이러한 자연어를 데이터를 분석하는데 사용되는 컴퓨터가 인식할 수 있도록 인공어(Artificial Language)로 만들어주는 것이 바로 자연어 처리 기술입니다.
노래 가사의 키워드(명사)만을 뽑는 과정도 자연어 처리의 일부라고 할 수 있습니다.
100개의 가사를 모두 이해해서 명사만 추출해야 하기 때문이죠! 자 그러면 명사는 어떻게 구분할 수 있을까요??
학창시절 재미없고 졸렸던 국어 시간의 기억을 되살려 봅시다.
국어 시간에 우리는 의미를 가지는 가장 작은 말의 단위인 '형태소'에 대해서 배웠습니다. 기억이 가물가물할 여러분을 위해 이해가 한번에 가는 그림을 가져왔습니다!

위 그림을 보아 형태소를 쪼개서 명사를 찾을 수 있다는 것을 알 수 있습니다.
우리는 단어 단위로 형태소를 분석하여 명사를 찾을 겁니다. 그리고 이러한 과정을 형태소 분석이라고 합니다.
파이썬에는 한국어의 자연어 처리를 도와주는 라이브러리 koNLPy 가 있습니다.
koNLPy 는 여러가지 형태소 분석기(말뭉치)를 가지고 있는데요, 목록은 다음과 같습니다.
- Hannanum - KAIST 말뭉치를 이용해 생성된 사전Hannanum - KAIST 말뭉치를 이용해 생성된 사전
- Kkma - 세종 말뭉치를 이용해 생성된 사전 (꼬꼬마)Kkma - 세종 말뭉치를 이용해 생성된 사전 (꼬꼬마)
- Mecab - 세종 말뭉치로 만들어진 CSV형태의 사전Mecab - 세종 말뭉치로 만들어진 CSV형태의 사전
- Komoran- Java로 쓰여진 오픈소스 한글 형태소 분석기Komoran- Java로 쓰여진 오픈소스 한글 형태소 분석기
- Twitter(Okt) - 오픈소스 한글 형태소 분석기Twitter(Okt) - 오픈소스 한글 형태소 분석기
우리는 오늘 Okt를 사용할 건데요, Okt는 노래가사처럼 띄어쓰기와 맞춤법이 어느정도 지켜졌다면 좋은 성능을 보여줍니다.
본격적인 데이터 분석을 시작하기 전에 우선 외부 라이브러리인 koNLPy를 설치해야겠죠??
파이참에서 koNLPy를 설치하기 전에 주의 해야할 것들이 있습니다. koNLPy는 JAVA가 필요하기 때문에 JAVA가 없다면 설치해 주어야 합니다.
koNLPy 설치하기
- 윈도우 메뉴 옆 검색에서 'cmd'를 검색한 후 관리자 권한으로 실행합니다.윈도우 메뉴 옆 검색에서 'cmd'를 검색한 후 관리자 권한으로 실행합니다.
java -version
java -version위 코드를 입력한 후 버전을 확인합니다. 자바를 검색할 수 없다면 java를 설치해야 합니다.
2. JDK(java development kit) 에 들어가 JDK를 자신의 OS에 맞는 걸로 다운로드 하여 설치합니다. (로그인 해야합니다..)
*버전은 상관없으나 1.7(8) 버전 이상으로 다운받아 주시기 바랍니다.

설치에서는 특별히 설정해야하는 것이 없음으로 모두 '다음'을 눌러 설치 합니다.
3. java의 환경변수를 설정해 주시기 바랍니다.
<환경 변수 설정하기>
1. 자바가 설치된 폴더를 엽니다. 보통 C:\Program Files\Java\jdk-11.0.7 으로 jdk-11.* 같이 버전으로 구성된 폴더 이름으로 저장됩니다.
2. 윈도우 메뉴 옆 '검색' 버튼을 눌러 [시스템 환경 변수 편집]를 찾아 엽니다.
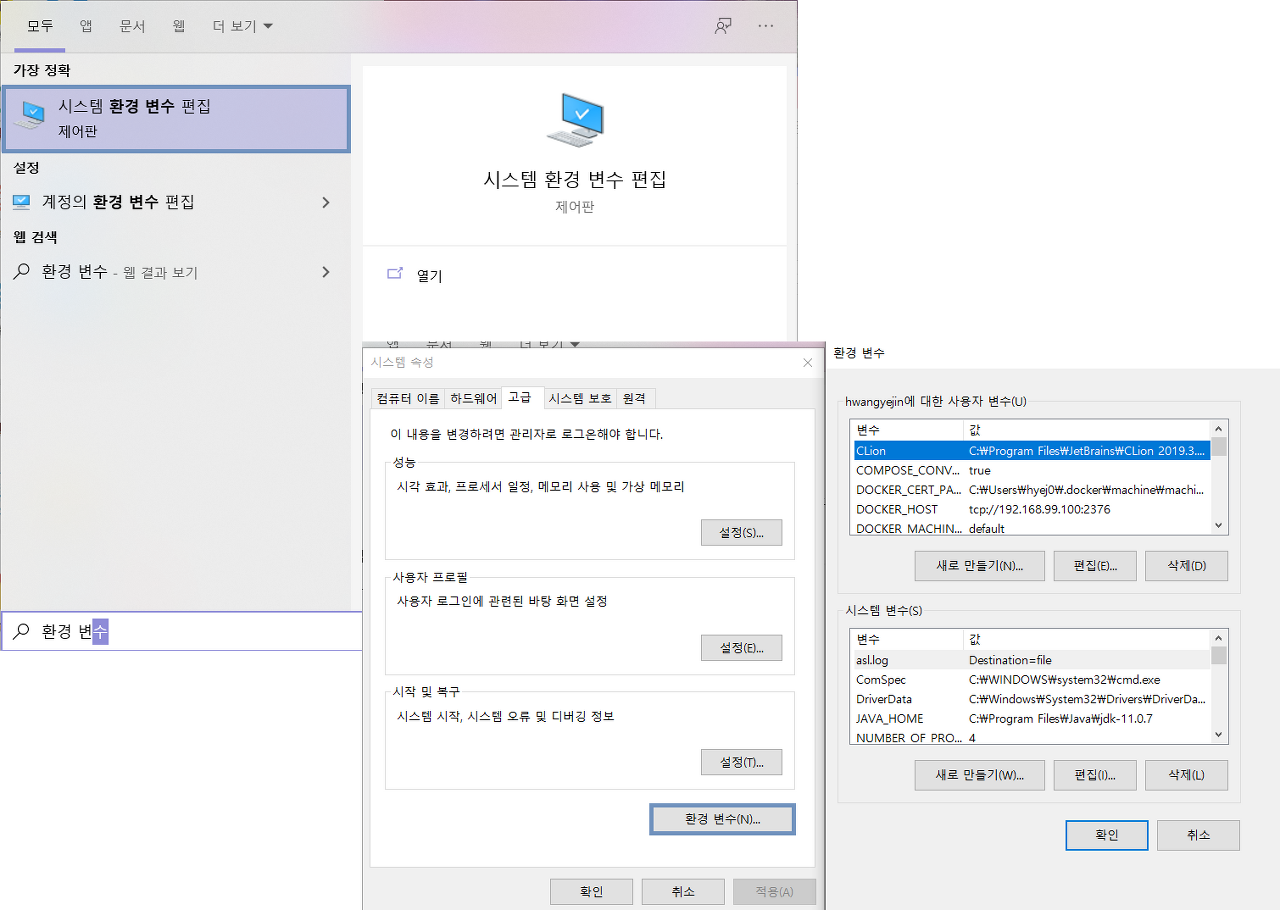
3. 시스템 변수에서 [새로 만들기]를 누르고 아래와 같이 설치한 jdk의 경로로 JAVA_HOME을 추가합니다.
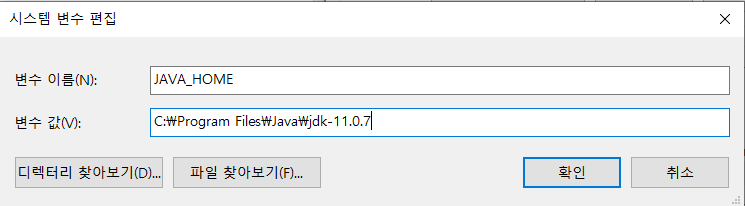
4. 시스템 변수에서 변수 [Path] 를 찾아 [편집]을 누른 후 [추가하기]를 눌러 환경변수 JAVA_HOME을 추가합니다. 아래 코드를 복사하면 됩니다.
%JAVA_HOME%\bin
잘 설치하고 설정했다면 cmd에서 아래 구문을 입력하여 이미지 처럼 자바 버전이 잘 나오는지 확인합니다.
javac -version
자바를 성공적으로 설치했다면 다시 파이참으로 돌아와 봅시다!
파이참에서 JAVA를 불러오기 위해서는 파이참과 JAVA를 연결해주는 JPype1라는 모듈을 설치해 주어야합니다.
JPype1 설치하기JPype1 설치하기
- PyCharm의 메뉴 바에서 File -> Settings를 클릭합니다. (macOS의 경우 상단 바의 PyCharm -> preferences)PyCharm의 메뉴 바에서 File -> Settings를 클릭합니다. (macOS의 경우 상단 바의 PyCharm -> preferences)
- Project: Practice -> Project interpreter에서 패키지 리스트 아래의 + 버튼을 클릭합니다.Project: Practice -> Project interpreter에서 패키지 리스트 아래의 + 버튼을 클릭합니다.
- Available Packages 창에서 jpype1을 검색한 후 install package를 눌러 설치해줍니다.Available Packages 창에서 jpype1을 검색한 후 install package를 눌러 설치해줍니다.
koNLPy 설치하기koNLPy 설치하기
- PyCharm의 메뉴 바에서 File -> Settings를 클릭합니다. (macOS의 경우 상단 바의 PyCharm -> preferences)PyCharm의 메뉴 바에서 File -> Settings를 클릭합니다. (macOS의 경우 상단 바의 PyCharm -> preferences)
- Project: Practice -> Project interpreter에서 패키지 리스트 아래의 + 버튼을 클릭합니다.Project: Practice -> Project interpreter에서 패키지 리스트 아래의 + 버튼을 클릭합니다.
- Available Packages 창에서 konlpy를 검색한 후 install package를 눌러 설치해줍니다.Available Packages 창에서 konlpy를 검색한 후 install package를 눌러 설치해줍니다.



* 모듈 설치에서 pip 관련 에러가 뜬다면 모듈 설치 에서 'pip'을 검색하고 오른쪽 하단에 'Specify version'을 2.1로 설정 후 설치해주시기 바랍니다.
1.3 워드 클라우드 만들어보기
워드 클라우드는 일종의 그래프이기 때문에 워드 클라우드를 그리기 위해서는 시각화를 도와주는 matplotlib와 wordcloud라는 라이브러리를 설치해야 합니다.
matplotlib와 wordcloud 설치하기
- PyCharm의 메뉴 바에서 File -> Settings를 클릭합니다. (macOS의 경우 상단 바의 PyCharm -> preferences)
- Project: Practice -> Project interpreter에서 패키지 리스트 아래의 + 버튼을 클릭합니다.
- Available Packages 창에서 matplotlib와wordcloud 를 검색한 후 install package를 눌러 설치해줍니다.
방금 koNLPy를 설치한 것처럼 위 라이브러리 2개를 설치하고 Okt와 함께 불러와 봅시다!
# 텍스트 분석 라이브러리
from konlpy.tag import Okt
from wordcloud import WordCloud
import matplotlib.pyplot as plt
그렇다면 이제 워드 클라우드를 그려보도록 하겠습니다!
워드 클라우드는 wordcloud 라이브러리의 WordCloud 로 생성합니다.
#워드 클라우드 만들기
font_path = r'C:\Windows\Fonts\malgun.ttf' ## 맥의 경우 '/Library/Fonts/AppleGothic.ttf'
wordcloud = WordCloud(font_path = font_path, background_color='white', width = 800, height = 800)
데이터를 직접적으로 넣기전에 글씨체, 배경색, 크기를 미리 정해서 저장합니다. 글씨체는 글씨체파일의 경로로 설정을 해주어야 합니다.
운영체제 별로 폰트 저장 폴더가 다르기 때문에 맥북을 사용한다면 주석의 주소로 바꿔주세요!
워드 클라우드를 그리기 위해서는 워드 클라우드로 바꿀 텍스트가 필요합니다.
우리는 일단 워드 클라우드를 그려볼 것이기 때문에 애국가로 테스트를 진행하겠습니다.
text = """
동해물과 백두산이 마르고 닳도록
하느님이 보우하사 우리나라 만세
무궁화 삼천리 화려강산 대한사람 대한으로 길이 보전하세
남산위에 저 소나무 철갑을 두른듯
바람서리 불변함은 우리기상 일세
무궁화 삼천리 화려강산 대한사람 대한으로 길이 보전하세
가을하늘 공활한데 높고 구름없이
밝은달은 우리가슴 일편단심일세
무궁화 삼천리 화려강산 대한사람 대한으로 길이 보전하세
이 기상과 이 맘으로 충성을 다하여
괴로우나 즐거우나 나라사랑하세
무궁화 삼천리 화려강산 대한사람 대한으로 길이 보전하세
"""
wordcloud = wordcloud.generate(text)
# 표 그림
fig = plt.figure(figsize=(7,7))
plt.imshow(wordcloud)
plt.axis("off")
plt.show()
위 코드를 실행하면 다음과 같이 워드 클라우드가 생성됩니다.

우리나라 애국가에는 무궁화와 삼천리, 화려강산이란 단어가 많이 나오는 것을 확인할 수있습니다.
아쉬운 점이 있다면 우리는 애국가를 형태소분석을 하지 않았기 때문에 명사로만 이루어진 워드 클라우드가 아니라는 점이 있습니다.
우리의 아쉬움을 충족해 주기 위해 이전 강의에서 크롤링한 가요차트 top 100의 가사들은 형태소 분석을 한 후에 워드 클라우드로 만들어 봅시다!
100곡의 가사로 워드 클라우드 만들기
1.1 명사 구분하기
지난 강의에서 가져온 top 100 의 노래가사를 가져왔습니다. 혹시 가져온 데이터를 어떤 형식으로 저장했는지 기억나시나요?

위 사진 처럼 하나의 문자열 형태로 songs 리스트에 담아 저장을 했었습니다. 반복문을 사용해서요!
그렇다면 반대로 하나하나 추출하는 것도 반복문을 사용하여 가져올 수 있을 것입니다.
반복문을 사용해서 우리는 하나의 노래가사를 명사만 뽑아 새로운 리스트에 추가하는 작업을 해야합니다.
t = Okt()
token_ko = []
# 각 노래 별 명사 추출
for text in songs:
token_ko += t.nouns(text)
koNLPy의 nouns() 함수는 해당 문자열에서 명사를 추출하여 리스트 형식으로 반환해 주는 함수입니다.
반복문 아래에 print(token_ko) 를 작성하여 명사가 잘 추출되었는지 확인해 봅시다!

두 번째 줄에 명사만으로 이루어진 리스트가 출력되는 모습을 확인할 수 있습니다. 잘 추출된 것 같네요!
저는 시간을 단축하기 위해서 노래 2개의 가사만 출력되어 짧지만 top 100의 노래가사의 명사를 모두 추출하면 길이가 상당이 길어질 겁니다.
한 글자로 구분된 명사가 거슬린다면 아래 코드로 한 글자 명사들을 지워봅시다!
# 한 자리 수 단어 제거 for i, v in enumerate(token_ko): if len(v) < 2: token_ko.pop(i)
# 한 자리 수 단어 제거
for i, v in enumerate(token_ko):
if len(v) < 2:
token_ko.pop(i)enumerate() 라는 함수는 “열거하다”라는 뜻이며. 이 함수는 순서가 있는 자료형(리스트, 튜플, 문자열)을 입력으로 받아 인덱스 값을 포함하는 enumerate 객체를 반환합니다.
enumerate가 반환해 주는 index와 index에 해당하는 문자를 가지고 명사의 길이가 2미만이면 저장했던 리스트 token_ko에서 pop()함수로 i번째 요소를 제거하여 한 글자 명사를 없앨 수 있습니다!
1.2 top 100의 워드 클라우드
우리가 방금 만든 token_ko는 명사들의 빈도가 없기 때문에 워드 클라우드를 직접적으로 만들 수 없습니다.
그래서 새로운 라이브러리를 불러서 명사들의 빈도를 저장해 워드 클라우드를 그려봅시다!
nltk라이브러리에서 koNLPy 같은 자연어 처리를 도와주는 라이브러리 입니다. 외부 라이브러리이기 때문에 설치가 필요합니다.
nltk 설치하기
- PyCharm의 메뉴 바에서 File -> Settings를 클릭합니다. (macOS의 경우 상단 바의 PyCharm -> preferences)
- Project: Practice -> Project interpreter에서 패키지 리스트 아래의 + 버튼을 클릭합니다.
- Available Packages 창에서 nltk를 검색한 후 install package를 눌러 설치해줍니다.
import nltk
nltk에서 제공하는 nltk.Text()는 문서 하나를 편리하게 탐색할 수 있는 다양한 기능을 제공합니다.
또한 nltk.vocab()는 각 단어의 빈도 분포를 반환합니다. 여기에 콜렉션의 most_common() 함수는 빈도가 높은 상위 몇개의 요소를 반환합니다.
이 3개의 함수를 사용해서 워드 클라우드를 그려보겠습니다!
ko = nltk.Text(token_ko, name = "바이브 차트 텍스트 클라우드")
# 상위 단어 100 선정
most_nouns = ko.vocab().most_common(100)
# 워드 클라우드 생성
wordcloud = wordcloud.generate_from_frequencies(dict(most_nouns))
#wordcloud = wordcloud.generate(text)
# 표 그림
fig = plt.figure(figsize=(7,7))
plt.imshow(wordcloud)
plt.axis("off")
plt.show()# 표 그림 주석 윗 부분을 위와 같이 변경하여 작성해 주세요!
실행하면 조금 오래걸리지만 top 100의 노래가사를 가져와 워드 클라우드가 그려집니다!

위에 처럼 잘 그려졌나요? 예측했던 대로 우리나라 가요는 ❤사랑❤과 관련이 있어보이네요!
1.3 워드 클라우드 모양 바꾸기
이번 강의 첫 장에서 봤던 워드 클라우드를 기억하나요??
그 워드 클라우드의 모양은 ☁구름모양☁이었습니다! 우리도 한번 워드 클라우드의 모양을 바꿔 볼까요?
모양을 변경하려면 numpy와 1차 세미나에서 사용했던 PIL 라이브러리가 필요합니다.
numpy와 PIL 설치하기
- PyCharm의 메뉴 바에서 File -> Settings를 클릭합니다. (macOS의 경우 상단 바의 PyCharm -> preferences)
- Project: Practice -> Project interpreter에서 패키지 리스트 아래의 + 버튼을 클릭합니다.
- Available Packages 창에서 numpy와 Pillow를 검색한 후 install package를 눌러 설치해줍니다.
성공적으로 설치가 완료되었다면 불러와 봅시다!
import numpy as np from PIL import Image
모양을 바꾸려면 바꿀 모양의 마스킹 이미지가 필요합니다.
아래 이미지를 다운로드 하여 'alice_mask.png'로 저장 후 프로젝트 폴더에 넣어주세요!

PIL 라이브러리의 Image로 우리가 마스킹할 이미지를 불러옵니다.
numpy를 사용하여 배열로 만들고 우리가 맨 처음에 생성한 wordcloud 의 mask 속성에 넣어줍니다.
# 마스크 생성
mask = np.array(Image.open("alice_mask.png"))
font_path = r'c://windows/fonts/malgun.ttf'
wordcloud = WordCloud(font_path = font_path, background_color='white', mask = mask, width = 800, height = 800)실행해 볼까요?

앨리스 모양의 워드 클라우드가 만들어 졌네요!
이번 강의는 여기까지 입니다! 여러분의 첫 워드 클라우드는 어떠셨나요? 즐거우셨나요?
강의를 함께하신 모든 부원들께서 데이터를 다루는 즐거움을 알아가는 시간이 되었으면 좋겠습니다.
수고하셨습니다😊
전체코드
# 크롤링 라이브러리
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
# 텍스트 분석 라이브러리
import matplotlib.pyplot as plt
import nltk
from konlpy.tag import Okt
from wordcloud import WordCloud
# 텍스트 클라우드 모양 변경 라이브러리
import numpy as np
from PIL import Image
driver = webdriver.Chrome('C://chromedriver.exe')
driver.maximize_window()
driver.get('https://vibe.naver.com/chart/genre-DS101')
driver.find_element_by_css_selector('#app > div.modal > div > div > a').click()
songs = []
for i in range(1, 101):
button = driver.find_element_by_css_selector('#content > div.track_section > div:nth-child(1) > div > table > tbody > tr:nth-child('+str(i)+') > td.lyrics')
if(button.text != ''):
button.click()
lyrics = WebDriverWait(driver, 3).until(
EC.visibility_of_element_located((By.CSS_SELECTOR, '#app > div.modal > div > div > div.ly_contents > p > span:nth-child(2)'))
)
lyrics_data = lyrics.text.replace('\n', ' ')
songs.append(lyrics_data)
close = driver.find_element_by_css_selector('#app > div.modal > div > div > a')
close.click()
if i%10==0:
driver.execute_script("arguments[0].scrollIntoView(true);", button)
print(songs)
# 마스크 생성
mask = np.array(Image.open("alice_mask.png"))
font_path = r'c://windows/fonts/malgun.ttf'
wordcloud = WordCloud(font_path = font_path, background_color='white', mask = mask, width = 800, height = 800)
t = Okt()
token_ko = []
# 각 노래 별 명사 추출
for text in songs:
token_ko += t.nouns(text)
print(token_ko)
# 한 자리 수 단어 제거
for i, v in enumerate(token_ko):
if len(v) < 2:
token_ko.pop(i)
print(token_ko)
ko = nltk.Text(token_ko, name = "바이브 차트 텍스트 클라우드")
# 상위 단어 100 선정
most_nouns = ko.vocab().most_common(100)
# 워드 클라우드 생성
wordcloud = wordcloud.generate_from_frequencies(dict(most_nouns))
# 표 그림
fig = plt.figure(figsize=(7,7))
plt.imshow(wordcloud)
plt.axis("off")
plt.show()
참고
'❤ 25기 > 25기 세미나' 카테고리의 다른 글
| [25기 세미나] PyQt5로 그림판 만들기(2) (0) | 2021.03.03 |
|---|---|
| [25기 세미나] PyQt5로 그림판 만들기(1) (0) | 2021.03.03 |
| [25기 세미나] Selenium으로 솔룩스 공식 사이트에 자동으로 댓글 달기(2) (0) | 2021.03.03 |
| [25기 세미나] Selenium으로 솔룩스 공식 사이트에 자동으로 댓글 달기(1) (0) | 2021.03.03 |
| [25기 세미나] BeautifulSoup와 tkinter로 웹툰 뷰어 만들기(2) (0) | 2021.03.03 |



